
끄적끄적
CH 3. 심화 프로젝트 - 데이터전처리 본문
사용하는 데이터
🧪 데이터
1. card_data.csv
| 컬럼 | 설명 |
| id | 카드 ID(카드 고유 식별자) |
| client_id | 고객 ID |
| card_brand | 카드 브랜드 |
| card_type | 카드 유형 |
| card_number | 카드 번호 |
| expires | 만료기간 |
| cvv | 카드 보안 코드 |
| has_chip | 칩 유무(마그네틱 카드와 IC카드 구분) |
| num_cards_issued | 발급된 카드 총 개수 |
| credit_limit | 카드 한도 |
| acct_open_date | 계좌 개설 날짜 |
| year_pin_last_changed | PIN 마지막 변경 연도 |
| card_on_dark_web | 다크웹에서 카드 정보 발견 여부 |
2. transactions_data.csv
| 컬럼 | 설명 |
| id | 거래 고유 ID |
| date | 거래 날짜 |
| client_id | 고객 ID |
| card_id | 사용된 카드 ID |
| amount | 거래 금액 |
| use_chip | 칩 사용 여부 |
| merchant_id | 가맹점 고유 ID. |
| merchant_city | 가맹점 위치(도시) |
| merchant_state | 가맹점 위치(주) |
| zip | 가맹점 우편번호 |
| mcc | 가맹점 업종 코드 : 금융 서비스에서 제공하는 상품 또는 서비스 유형에 따라 부여되는 4자리 숫자입니다. |
| errors | 거래 중 발생한 오류 (있다면 상세 코드) |
3. users_data.csv
| 컬럼 | 설명 |
| id | 고객 ID |
| current_age | 나이 |
| retirement_age | 예상 은퇴 나이 |
| birth_year | 출생 연도 |
| birth_month | 출생 월 |
| gender | 성별 |
| address | 주소 |
| latitude | 주소의 위도 |
| longitude | 주소의 경도 |
| per_capita_income | 1인당 소득 |
| yearly_income | 연간 소득 |
| total_debt | 총 부채 |
| credit_score | 신용 점수 |
| num_credit_cards | 보유 신용카드 수 |
데이터 설명
고객 정보, 거래 정보, 카드 정보를 담은 3가지 데이터가 존재한다.
해당 데이터는 각 client_id, card_id를 통해 merge 할 수 있다.
과제 설명
🧪 데이터셋은 총 3개의 CSV 파일로 구성되어 있습니다.
- 해당 데이터셋은 2024년 AI 해커톤을 위해 만들어졌습니다.
- 테이블 간 관계를 파악하여, 클러스터링을 위한 하나의 Dataframe 으로 만들어주세요.
🧪 필수 사항
- 이상치 처리 기법을 활용하거나, 특정 기준을 세워 이상치를 정의 하고 그 이유를 설명해주세요.
- 클러스터링시, 초기 군집의 갯수와 사용할 컬럼의 갯수는 python 머신러닝 라이브러리를 활용하여 진행해주세요.
- 컬럼별 raw data 분포를 그려주세요.
- 컬럼 간 상관계수를 히트맵 차트로 구현해주세요.(유의미한 기준은 +0.6(양의 상관관계) 또는 -0.6(음의 상관관계)으로 판단해주시면 됩니다)
🧪 선택 사항
- 필요하다면 파생변수를 생성해도 좋습니다.
- 데이터 표준화가 필요한 경우 진행해주세요. 표준화 방법을 여러가지 사용해보시고, 비교해주셔도 됩니다.
- 범주형 데이터를 사용할 경우, 인코딩을 진행해주세요. 원-핫 인코딩/라벨인코딩 모두 사용해도 됩니다. 다만, 범주의 갯수가 많은 경우, 별도 세그멘테이션이 필요할 수 있겠습니다. 의미있는 기준을 세워주시고 그 값을 인코딩 진행해주세요. (예시: 국가가 100개인 경우 육대륙으로 나누어 인코딩). 참고자료: https://nicola-ml.tistory.com/62#google_vignette
- 분석 결과를 한 눈에 파악할 수 있도록 datapane 또는 streamlit 으로 리포트를 구현해주세요.
분석 목표: 리스크 관리 전략 수립
분석 방향
아래 2가지 리스크를 고려하였다.
1. 신용 리스크
신용 점수, 부채 등 칼럼을 사용해 고객의 신용 리스크 별로 군집을 구하자.
그 중 고위험군, 즉 채무 불이행 가능이 높은 고객에게 대응하는 방법을 탐색하자.
2. 운영 리스크
보안 측면에서의 고객 군집을 구하자.
그 중 보안이 취약해 보이는 고객에게 대응하는 방법을 탐색하자.
데이터에 존재하는 결측치는 일단 신경쓰지 않고 진행하였다.
why? 우리가 사용할 컬럼에 속해있지 않았기 때문이다.
1. Card Data


Null 값은 존재하지 않았다.
추가로 object 타입의 데이터를 살펴보니 'credit_limit'이 '$문자열' 형태로 되어있어 이를 숫자형으로 변환하였다.

category_card = card.select_dtypes(['object'])
for c in category_card.columns:
if c not in ['acct_open_date', 'expires']:
print(f'{c}: {card[c].unique()}')
# 문자열 제거
card['credit_limit'] = pd.to_numeric(card['credit_limit'].str.replace('$',''), errors='coerce')
아래의 4가지 경우를 이상치가 될 수 있다고 판단했다.
1. 카드 번호가 16/15자리인지
2. cvv 번호가 3/4자리인지
3. expires가 acct_open_date보다 빠른 경우
4. year_pin_last_changed가 acct_open_date보다 빠른 경우
-> cvv 번호가 2번에 해당하는 이상치가 존재해 제거
추가로 수치형 데이터를 Boxplot을 통해 살펴보았을 때, 일부 이상치가 있다고 나오지만
신용한도가 높은 경우는 고소득층에겐 가능하다 생각하여 이상치로 판단하지 않았다.
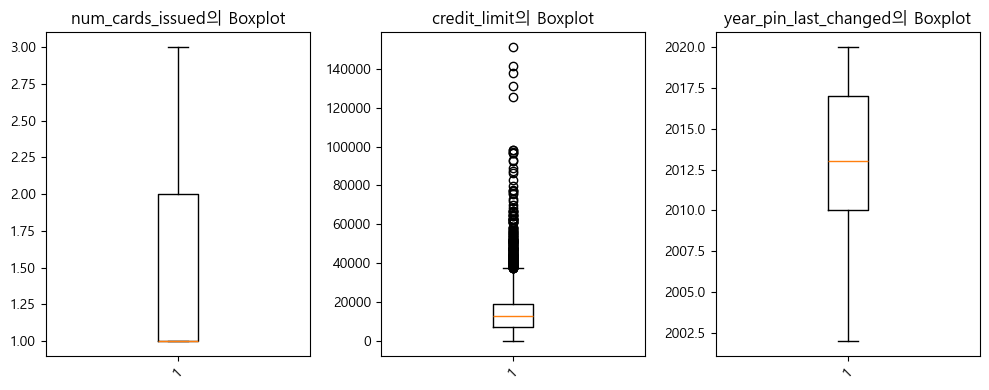
numeric_card_col = ['num_cards_issued','credit_limit', 'year_pin_last_changed']
fig, ax = plt.subplots(1,3,figsize=(10,4))
ax = ax.flatten()
for i,c in enumerate(numeric_card_col):
ax[i].boxplot(card[c])
ax[i].set_title(f'{c}의 Boxplot')
ax[i].tick_params(axis='x', rotation=45)
plt.tight_layout()
plt.show()
2. User Data


card 데이터와 마찬가지로 null 값이 없으며, 가격을 뜻하는 컬럼의 불필요한 문자열을 제거하고 수치형 데이터로 변환하였다.

category_user = user.select_dtypes(['object'])
for c in category_user.columns:
print(f'{c}: {user[c].unique()}')
# 타입 변경
user['per_capita_income'] = pd.to_numeric(user['per_capita_income'].str.replace('$',''), errors='coerce')
user['yearly_income'] = pd.to_numeric(user['yearly_income'].str.replace('$',''), errors='coerce')
user['total_debt'] = pd.to_numeric(user['total_debt'].str.replace('$',''), errors='coerce')
user 데이터의 이상치를 탐지하기 위해 Boxplot을 그려보면

소득에 관련된 데이터를 제외하면, 충분히 가능한 수치라 생각해서 'per_capita_income', 'yearly_income'만 고려한다.

IQR 이상치 제거를 수행하려고 했는데, 낮은 값에 치중이 되어있었고, 소득이 비정상적으로 낮은게 높은 것 보다 이상하다고 생각하여 로그변환을 수행해 Q1 - 1.5*IQR보다 작은 값을 제거해주었다.

fig, ax = plt.subplots(1,2,figsize=(12,4))
sns.histplot(user['yearly_income'], bins=50, ax=ax[0])
ax[0].set_title('yearly_income')
ax[0].tick_params(axis='x', rotation=45)
sns.histplot(user['per_capita_income'], bins=50, ax=ax[1])
ax[1].set_title('per_capita_income')
ax[1].tick_params(axis='x', rotation=45)
plt.show()
# 로그 변환
user['log_yearly_income'] = np.log(user['yearly_income'] + 1) # 0 대비 +1 처리
user['log_per_capita_income'] = np.log(user['per_capita_income'] + 1) # 0 대비 +1 처리
fig, ax = plt.subplots(1,2,figsize=(12,4))
sns.histplot(user['log_yearly_income'], bins=50, ax=ax[0])
ax[0].set_title('log_yearly_income')
ax[0].tick_params(axis='x', rotation=45)
sns.histplot(user['log_per_capita_income'], bins=50, ax=ax[1])
ax[1].set_title('log_per_capita_income')
ax[1].tick_params(axis='x', rotation=45)
plt.show()
# 연간 소득 이상
q1 = user['log_yearly_income'].quantile(0.25)
q3 = user['log_yearly_income'].quantile(0.75)
iqr = (q3 - q1)
user.drop(index=list(user[user['log_yearly_income']<=q1- 1.5*iqr].index), inplace=True)
# 1인 소득 이상
q1 = user['log_per_capita_income'].quantile(0.25)
q3 = user['log_per_capita_income'].quantile(0.75)
iqr = (q3 - q1)
user.drop(index=list(user[user['log_per_capita_income']<=q1- 1.5*iqr].index), inplace=True)
3. Transaction Data

우선 거래날짜 컬럼으로 거래년도, 거래월, 거래요일 컬럼을 추가 생성했다.

이후에 결측치를 찾았을 때, 존재하긴 했지만 우리가 이후에 사용할 컬럼에는 존재하지 않았기에 그냥 무시해주었다.
'errors' 컬럼의 존재하는 Nan 값은 에러가 발생하지 않았다는 의미로 'No'로 Nan 값을 채워주었다.
또한, Insufficient Balance인 상태만 필요하기에 나머지는 'Other'로 변경해주었다.
def error_category(x):
if 'Insufficient Balance' in x:
return 'Insufficient Balance'
elif x == 'No':
return x
else:
return "Other"
trans['errors'] = trans['errors'].apply(error_category)
Transaction도 앞선 데이터와 같이 가격 데이터를 필요없는 문자열 제거 후 수치형으로 변경하였다.
# 문자열 제거
trans['amount'] = pd.to_numeric(trans['amount'].str.replace('$',''), errors='coerce')
trans.head()
수치형 데이터를 가지고 Boxplot을 그렸을 때, 값이 -가 나오는 데이터가 존재하였다.
그러나, 이를 동일 client_id와 card_id, merchant_id인 데이터와 비교하니 결제 취소 데이터임을 파악하였다.


'[스파르타]내일배움캠프 데이터 분석 트랙 > Project' 카테고리의 다른 글
| CH 4. 실전 프로젝트 - 가설 검증 및 대시보드 생성 (4) | 2025.08.18 |
|---|---|
| CH 4. 실전 프로젝트 - 데이터 전처리 (1) | 2025.08.18 |
| CH 2. 기초 프로젝트 - 최종 정리 (1) | 2025.06.23 |
| CH 2. 기초 프로젝트 - 데이터 분석 (2) (2) | 2025.06.19 |
| CH 2. 기초 프로젝트 - 데이터 전처리 (2) (5) | 2025.06.18 |


